Setting parameters |
To specify parameter settings for tools in the model, you need to click the input node with the left mouse button. At this time, a parameter fill-in comment will appear in the parameter column on the right side of the page. Enter the parameter value that meets the format according to the comment requirements. After all the required parameters of the current tool are filled in, the frame line of the function node of the tool will change from gray to blue, so you can quickly check the filling status of the model parameters according to the color of the outer frame of the node.
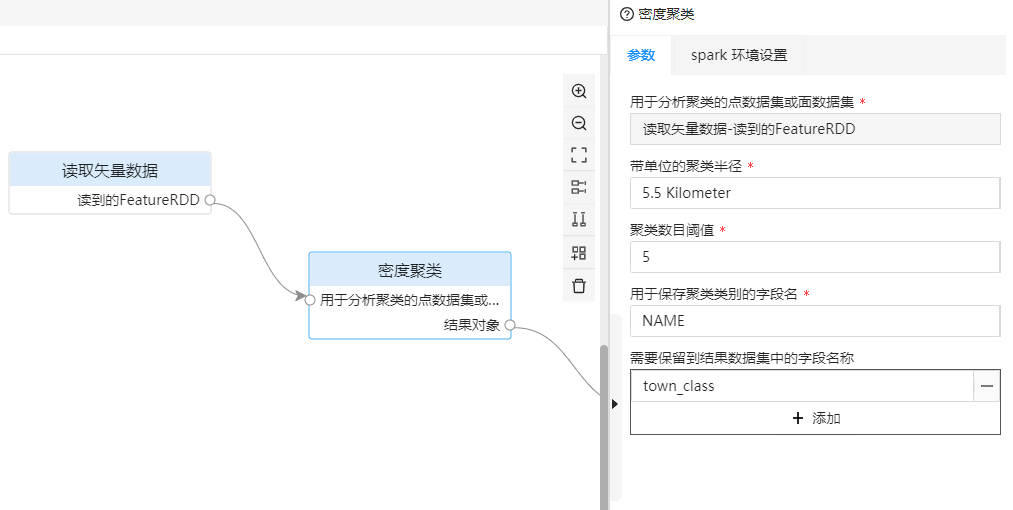
For urban density cluster analysis, the parameters that need to be filled in are as follows:
| tool name | parameter name | parameter definition | value |
|---|---|---|---|
| Read vector data | Connection information | Connection information of town data, the example here is the town data stored in HBase, you can import the sample data into Hbase. | --providerType=hbase --hbase.zookeepers=172.16.16.8:2181 --hbase.catalog=demo --dataset=Town_P |
| Density Clustering | Clustering Radius with Unit | Clustering Radius for Urban Density Clustering Analysis. | 5.5 Kilometer |
| Density Clustering | Density Clustering Threshold | Cluster number threshold for urban density clustering analysis, used to determine whether it is a core. | 5 |
| Density clustering | Field name used to save clustering categories | Field name used to save town clustering results. | town_class |
| Density clustering | The field name that needs to be kept in the result dataset | The result field name that needs to be kept in the town data, here only the name of the town is saved. | NAME |
| Save vector data | Connection information | Save the connection information of urban cluster analysis results. | --providerType=hbase --hbase.zookeepers=172.16.16.8:2181 --hbase.catalog=demo --dataset=Town_c |
By processing the modeler and using Apache Spark for distributed analysis of spatial big data, you should connect to the cluster and submit tasks before running the model. The parameter setting and output window on the right side of the processing modeler provides environment parameter settings. After setting the parameters, the processing modeler will connect to the cluster and submit processing automation tasks when running the model.
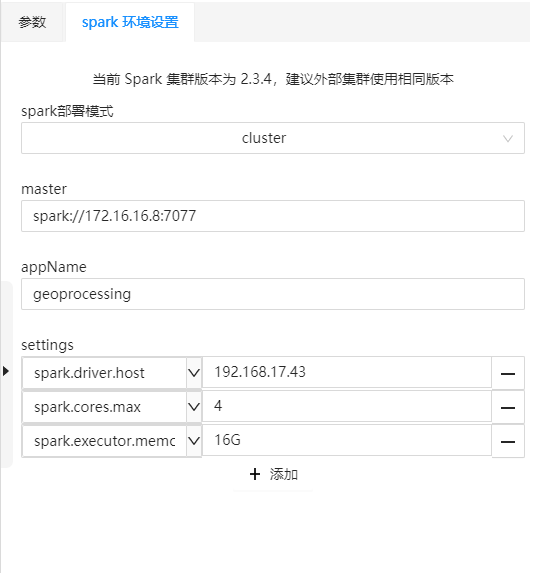
Cluster environment parameters include the following four parts:
Note: When Spark is version 2.3 or higher, the spark.driver.host parameter setting needs to be added to the configuration parameters to submit the Windows processing automation service tasks to the external cluster, and the parameter value is the IP address of the machine where the current application program is running. If the machine where the current application is located has multiple network cards, the value of this parameter needs to be an IP that can be accessed by the cluster. After setting the environment parameters, after running the model, you can connect to the Spark cluster and submit tasks to the cluster. The data reading and analysis tools used by the model will use the cluster connected to this parameter and the created task by default.