Share Directory |
You can use CSV files, UDB dataset files, and subfolders from shared or local file directories on the network, as well as TIFF and GeoTIFF raster data from local file directories for distributed analysis. Among them, after registering raster data (such as TIFF, GeoTIFF) stored in the local file directory to iServer, it can be distributed and stored in HDFS distributed repositories and local file system storage.
You can also use UDB dataset files and subfolders in a network share or local file directory for the machine learning service.
Log in to the iServer service management server, and click Data->Data Registration. Enter the register datastore page (http://{ip}:{port}/iserver/admin-ui/data/dataRegistration), click the Register Datastore button, and configure the following parameters:
Click the Register Datastore button to complete the registration.
When configuring the Share Directory, you can:
Depending on which Spark you decide to use Number of cluster nodes:
1. If there is only one Worker node in the Spark cluster, the data can be directly placed in a file path on the machine where the Worker node is located, such as:/ home/supermap/data
2. If there are multiple Spark Worker nodes, you can first set up a network share for the directory where the data is located, and map the shared directory to the local disk on the computer where the Worker nodes are located. It should be noted that each computer needs to be mapped and the drive letter set must be consistent. When iServer administrators register file directories, the "Share Directory" field is filled in with the mapped directory.
Recommendation: When there are multiple Spark Worker nodes, to avoid mapping drive letter conflicts, do not use the computer where the data is located as a Spark Worker node.
Based on the file types you register:
1. If registering UDB files, CSV files, TIFF, GeoTIFF raster data, directly fill in the directory path where the file is located, such as :/home/supermap/data
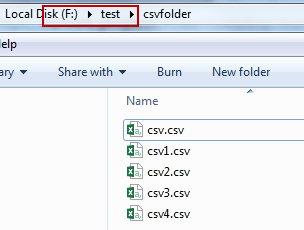
2. If you are registering a file directory with a CSV file, you need to fill in the directory above the directory where the CSV file is located. Take the following figure as an example, the path filled in is F:\file\test, where the fields, attributes and other formats of the CSV file must be the same. (Only supports opening CSV file directory in read-only mode)
Note: If you have registered a CSV data file, it needs to be validated before it can be used for distributed analysis services. See details: CSV data file verification.
The configuration steps are as follows: