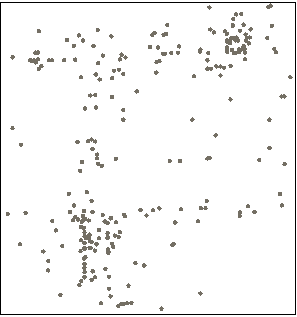
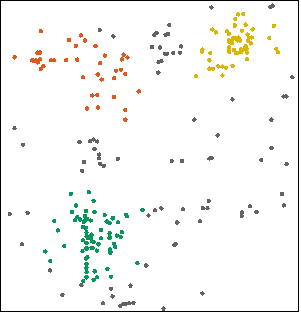
Spatial Density Clustering refers to the spatial clustering of a set of points. Using Density Clustering method DBSCAN, it can divide the region with high enough density into clusters, and can find clusters of arbitrary shape in the Spatial Data with noise.
Figure 1: Point object Figure 2: Results of implementing Spatial Density Clustering on point objects
Analyze Dataset: required parameter. The Dataset to be analyzed by Density Clustering needs to access Connection Info, including Data Type, Connect Parameter, Dataset name, etc. You can connect HBase data, dsf data, and Local Data.
Data Query Conditions: optional parameter; the specified data can be filtered out for corresponding analysis according to the Query Conditions; attribute conditions and Spatial Query are supported. E.g. SmID< 100 and BBOX(the_geom, 120,30,121,31)。
Cluster Radius: a required parameter. Sets the radius of the Aggregate Points, indicating that the number of points within the specified radius Is no less than threshold, indicating that the points are a category. Units are required for input, such as 1Kilometer. The supported units are Meter, Centimeter, Millimeter, Decimeter, Kilometer, Yard, Inch, Foot, Mile, Degree, Second, Minute, Radian, and the default unit is Meter.
Cluster Number Threshold: required parameter, used to display and set the minimum number of points clustered as one cluster. The value must be Greater than or equal to 2. The larger the threshold is, the more stringent the condition of clustering into a cluster is. The basis for judging whether it is the core. Note that the value is the number including itself.
Save field name of cluster category: required parameter, used for statistics of cluster category information. It is better to set it as a field name other than cluster, or it will automatically become NewField due to conflict with keywords.
Field to be reserved in the Result Dataset: optional parameter. You can choose to reserve the Specify Field in the original Dataset. By default, the field is reserved.
Result Dataset: required parameter, Output Analysis Result sDataset information, including Data Type, Connect Parameter, Dataset name, etc.
Spark context environment: optional parameter, the running environment of spark. The local mode is used by default, which means the spark environment of the local machine is used. In addition, the cluster environment can be set, and the ip and port number of the cluster can be set.